
믿는 도끼에 발등 찍힌 새 개발능력 벤치 DeepSWE 공개 결과
먼저 결과 한번 보시겠습니다.
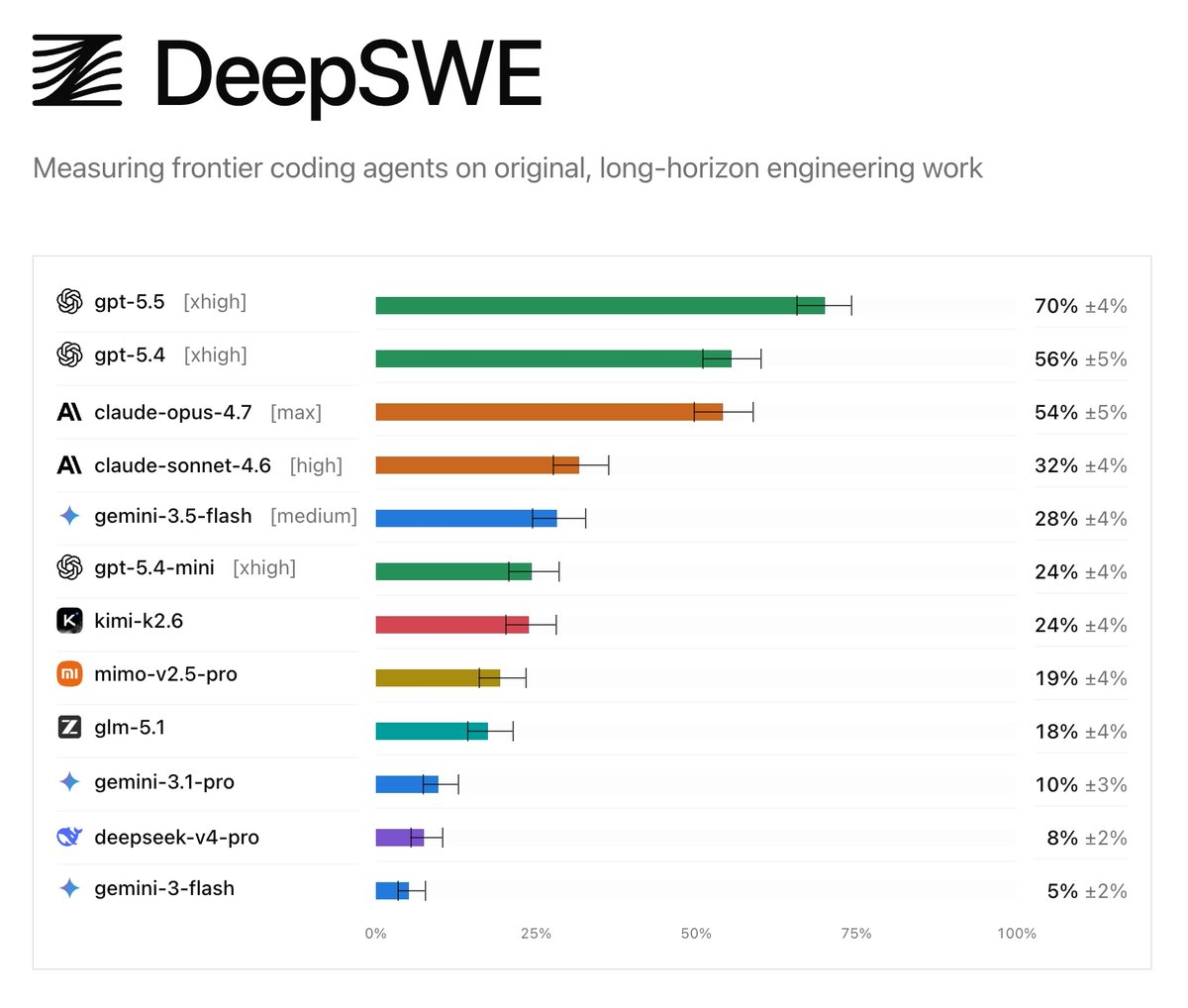
클로드만 믿었던 개발자들 많았죠. 특히 한국에… 제 주위에도 많아서 이상할 정도였죠. 하지만 이번 벤치로 인해 한순간 무너졌습니다.
대체 왜 이런 일이 일어났을까요?
기존 벤치가 상당히 취약점이 많았는데요. 답정너 수준의 정해진 답변과 이를 수행할 능력이 뛰어난 벤치다 보니 이렇게 된 겁니다.
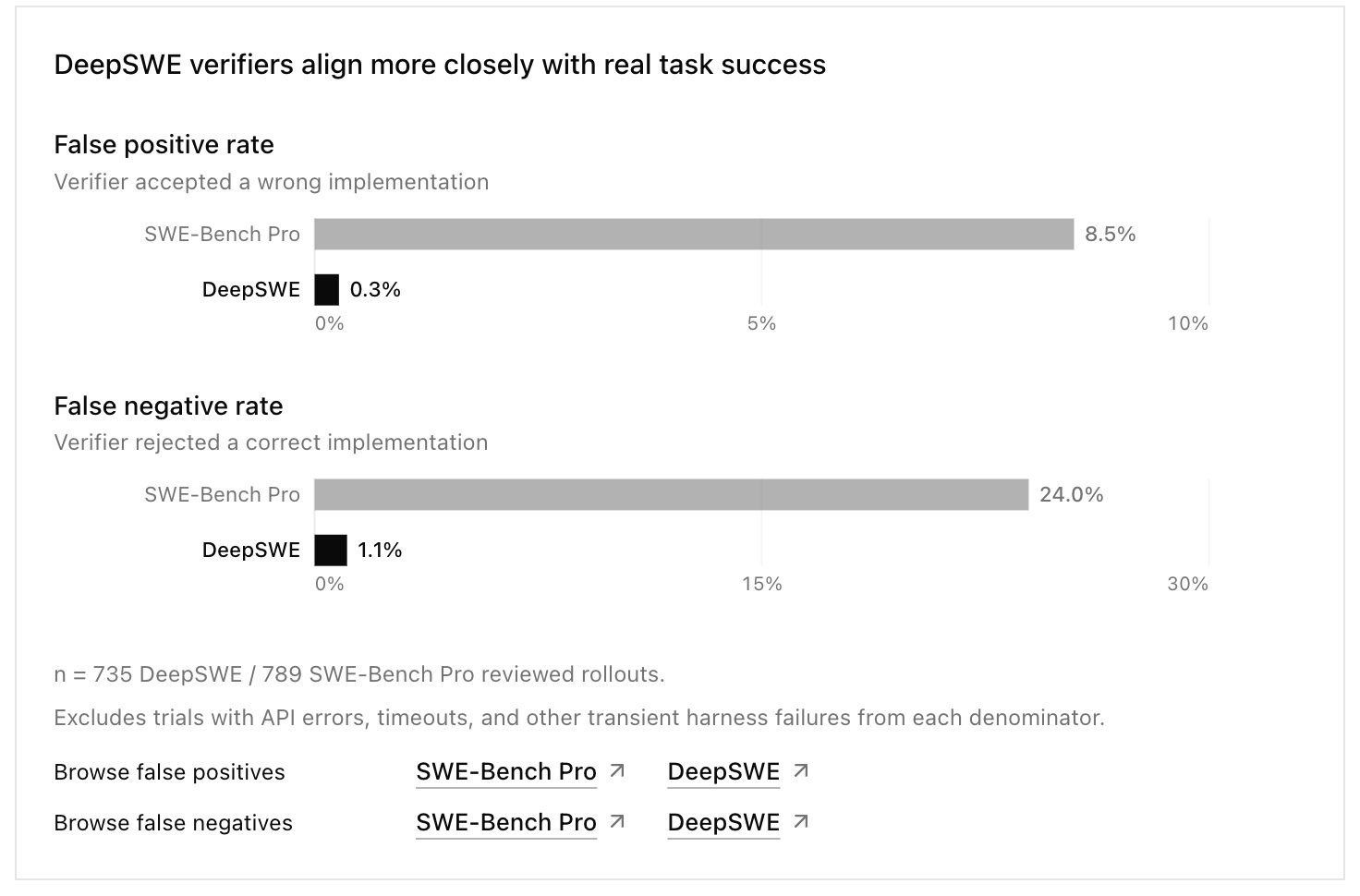
그래서 이렇게 오탐율이 많았고, DeepSWE는 이를 획기적으로 줄였습니다.
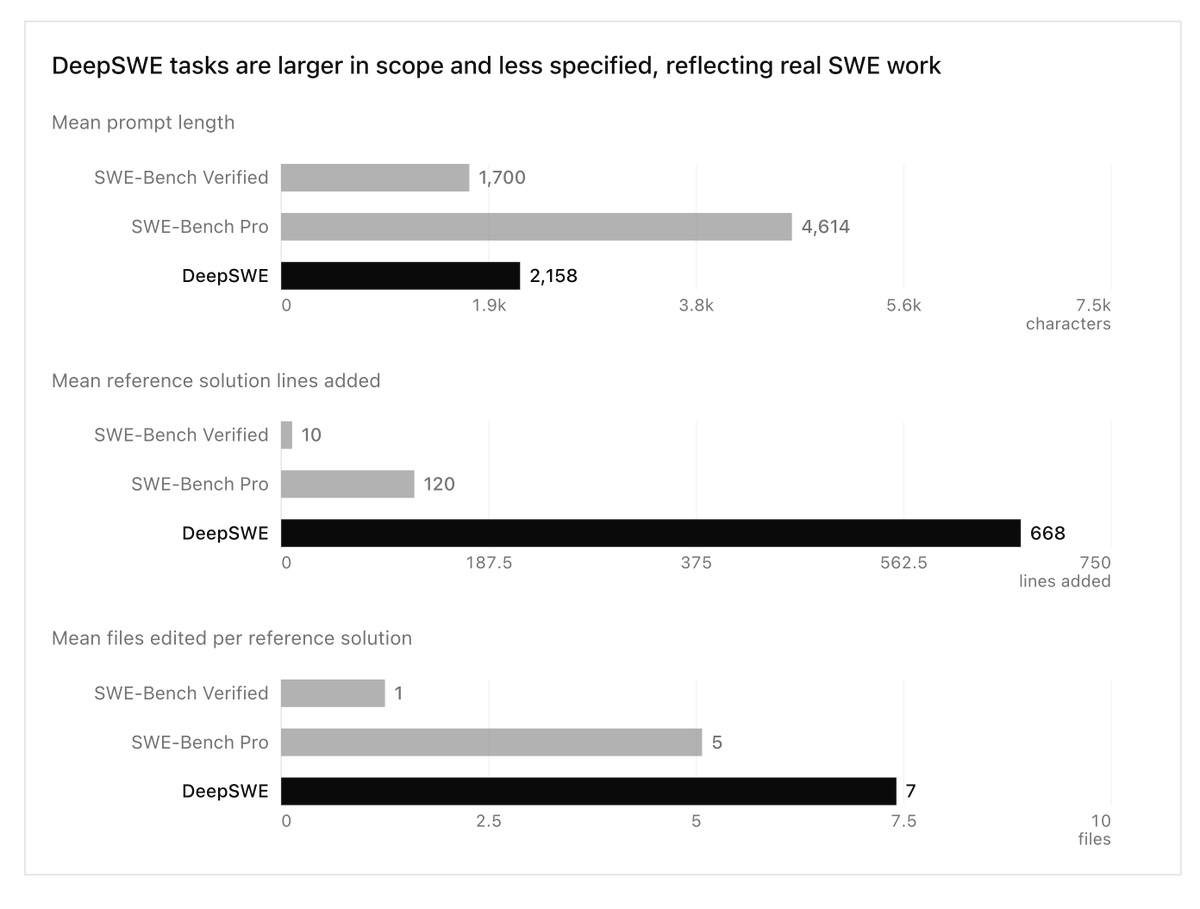
그리고 DeepSWE 를 처음부터 설계하면서 시각을 달리했는데요.
프롬프트는 기존보다 더 짧게, 코드는 더 길게, 수정 파일은 더 많아. 이런 식으로 개선했습니다.
그래서 나온 결과가 바로 첫번째 이미지로, 왜 이렇게 됐는지 부가 이미지와 같이 설명하자면,
Claude 모델은 효율성을 중시하는 전통답게 두 가지 작업을 동시에 구동하기 위한 프롬프트를 받으면 하나만 구현하고 나머지는 무시하는 경향이 많이 나타났습니다.
이에 반해 GPT 모델은 GPT 전통 답게 프롬프트 대로 움직이다 보니 기존 코드의 구조를 문맥을 파악하고 누락 없이 구현해 냈죠.
그럼 이전 벤치와 비교해 볼까요?
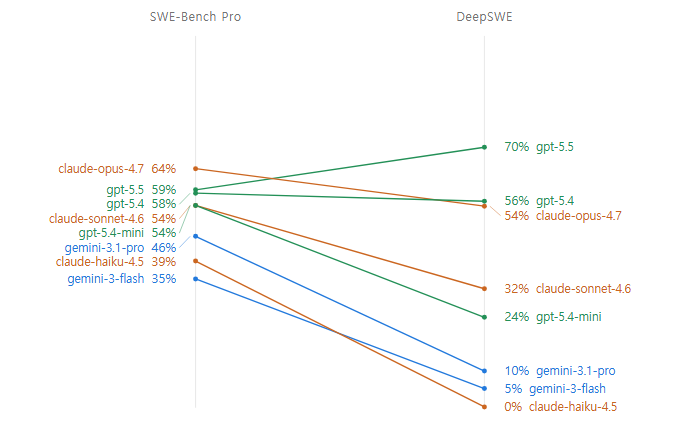
네. 작년부터 나타났던 개발자들의 의심이 확실시 되는 순간이 나타났습니다. 여태까지 너무 평균적이었던 분포도가… 보셨죠? 잼민아 보고있니?
게다가 여기서 측정한 토큰 가성비도 충격입니다.
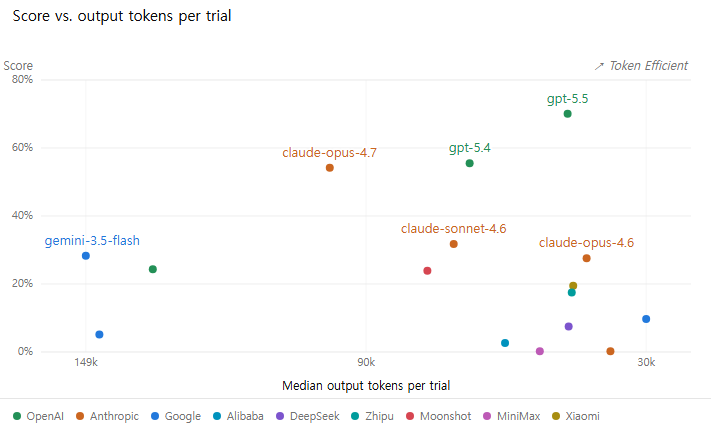
GPT가 토큰 가성비 대비 훌륭한 결과물을 보였고, 클로드는 Opus 4.6 시절이 오히려 가성비가 뛰어난 경향을 보였으며, sonnet 4.6 이 4.5에 비해 가성비가 떨어졌다는 체감이 든 개발자 의견들이 모두 맞아떨어지는 결과가 나타났습니다.
그리고 이번에 나온 재미나이 3.5는 네. 저도 돌려봤는기 기대 하나도 안했고 그 기대에 부응하는 결과를 보여줬습니다. 가성비 꽝에다가 결과물도 꽝. 구글은 그냥 하던 옴니에 집중하는게 나아 보일 정도죠.
저는 카톡으로 GPT 프로 대란 때 열심히 사서 쓰고 있는데, 그 사람들이 승리자가 아닌가 싶습니다.
이에 반해 클로드를 고집했던 개발자들은 이번 벤치에 대해 인정하는 반응이 대부분이지만 일부 애써 부정하는 반응도 만만찮죠.
조만간 오픈AI와 앤트로픽이 IPO에 들어갑니다. 과연 여러분들은 AI 모델을 보고 미래를 거시겠습니까? 아니면 재무재표와 인물들의 미래에 거시겠습니까?
읭 갑자기 왠 뜬금없는 IPO 얘기냐고요? 아이고 죄송. 아무튼 전체 내용은 아래 출처를 확인하시기 바랍니다.