
Opus 4.7 체감 성능 어떠신가요?
Opus 4.7 벤치마크를 보는게 의미가 있나 싶네요. (Gemini 3.1 이후로 벤치마크표를 안보게됨…)
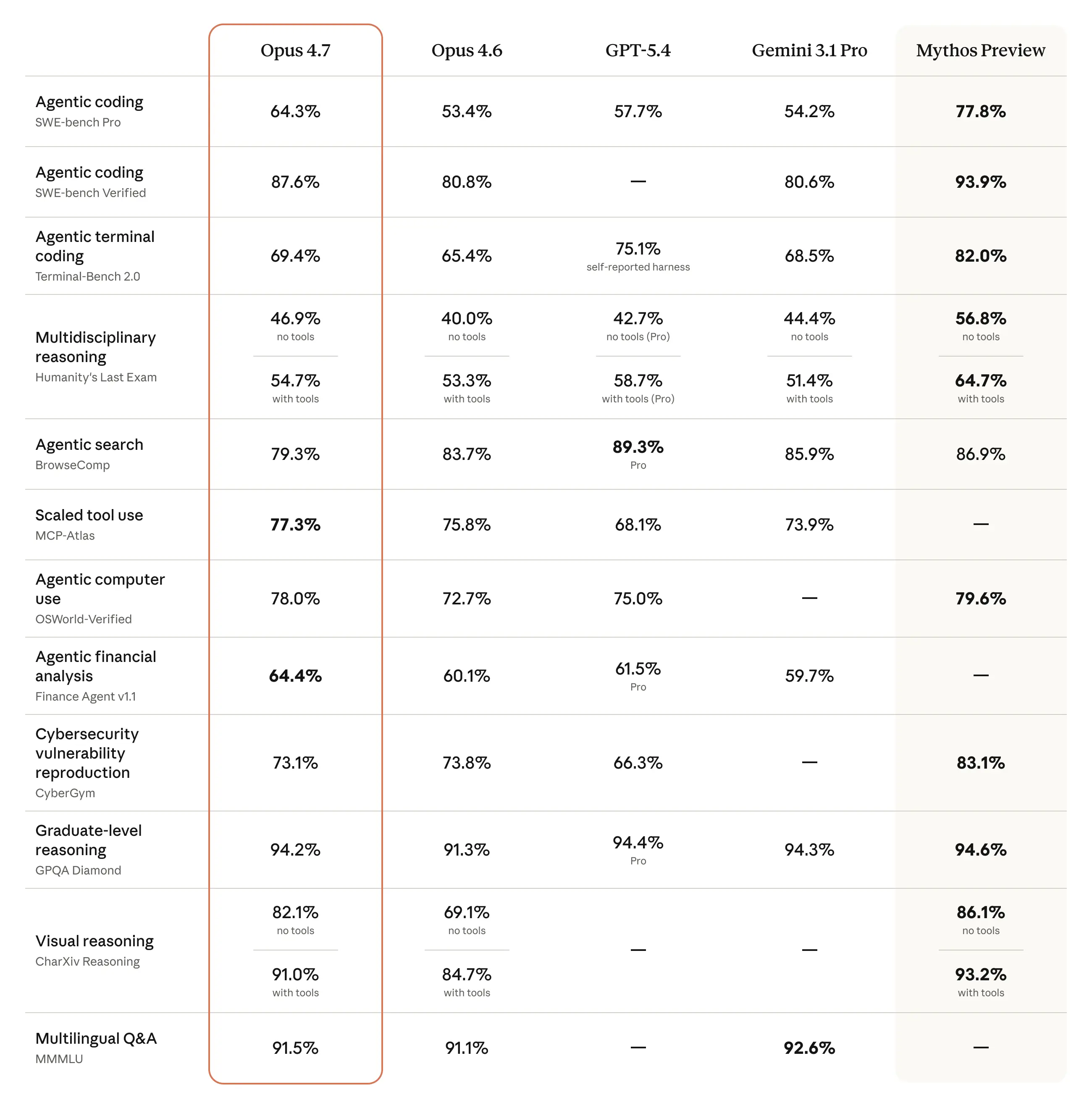
해커뉴스에 보니 이미 댓글 1,000개가 넘었더라구요. https://news.ycombinator.com/item?id=47793411 해커뉴스에서 Anthropic 모델 업데이트 관련 소식에 이렇게 부정적인 댓글이 많은건 처음보네요.
최근 2-3주 Opus 4.6 너프부터 쌓인 불만이 해소가 안된듯보여요.
그리고 이거 때문에 그냥 모델 변경해서 쓰면 잘하던거 못할 가능성도 있어요.
Opus 4.7 is substantially better at following instructions. Interestingly, this means that prompts written for earlier models can sometimes now produce unexpected results: where previous models interpreted instructions loosely or skipped parts entirely, Opus 4.7 takes the instructions literally. Users should re-tune their prompts and harnesses accordingly.
Opus 4.7은 지시사항 준수 능력이 크게 향상되었습니다. 흥미롭게도 이로 인해 이전 모델에 맞춰 작성된 프롬프트가 이제는 예상치 못한 결과를 초래하기도 합니다. 이전 모델들이 지시사항을 느슨하게 해석하거나 일부를 완전히 건너뛰었던 반면, Opus 4.7은 지시사항을 글자 그대로 엄격하게 받아들이기 때문입니다. 따라서 사용자는 이에 맞춰 프롬프트와 실행 환경(하네스)을 재조정해야 합니다.
Claude 쓰시는 분들 아직 이르긴 하지만 업데이트 만족하시나요??