나만의 Claude Code 워크플로우 (안전하게 사용하는 Yolo모드)
뮤테이션 테스트 기반 코딩 플랫폼(sdetcode.com)을 1인 개발하고 있습니다. 2026년 2월 한 달간 26개 피처를 프로덕션에 배포했습니다. 엔터프라이즈 B2B 멀티테넌시, AI 스킬 프로파일링 엔진, 전체 UI 리뉴얼까지 포함해서요.
핵심은 세 가지 시스템의 융합입니다:
Dev Life Cycle × PDCA 방법론 × Agent Teams
1. Dev Life Cycle: Git Worktree 기반 병렬 개발
Claude Code의 슬래시 커맨드로 Git 워크플로우 전체를 자동화합니다.
# 1단계: 격리된 개발 환경 생성
/dev-init "arcade-dashboard-enhancement"
# → feature/arcade-dashboard-enhancement 브랜치 생성
# → 별도 worktree 디렉토리에 체크아웃
# → .dev-session.json에 세션 메타데이터 기록
# 2단계: 개발 완료 후 배포
/dev-ship
# → 변경사항 분석 → 커밋 메시지 자동 생성
# → git push → EC2 SSH 접속 → docker-compose rebuild
# → 헬스체크까지 자동 수행
# 3단계: 정리
/dev-complete
# → main 병합 (squash or merge 선택)
# → worktree 제거 → 로컬/리모트 브랜치 삭제
# → 최종 프로덕션 배포
핵심 장점: 동시에 5개 세션을 병렬 실행합니다.
각 Claude 세션이 독립된 Git worktree에서 작업하므로 충돌이 없습니다. 세션 A가 백엔드 API를 만드는 동안, 세션 B는 프론트엔드 컴포넌트를, 세션 C는 번역을, 세션 D는 테스트를 작성합니다.
회사 실무에서는 이 사이클에 JIRA 티켓 번호를 브랜치명에 연동하고, 각 단계에서 작업 산출물(설계서, 분석서, 리포트)을 자동 생성하여 PM에게 전달하는 흐름으로 확장할 수 있습니다. (JIRA, Google Docs, Google Sheet MCP연동)
2. PDCA 방법론: AI가 스스로 요구사항 명세서를 작성한다
bkit PDCA 플러그인을 활용합니다. 이것이 가장 큰 게임체인저입니다.
Before (기존 워크플로우):
아이디어 구상
→ Gemini/ChatGPT로 기획서 초안 작성
→ 다른 LLM으로 크로스 체크
→ Codex/Claude로 코드베이스 vs 요구사항 간극 분석
→ LLM 재확인
→ 개발 시작
이 과정만 2-3시간, 때로는 반나절.
After (PDCA 워크플로우):
/pdca plan "Arcade Dashboard에 개인화 추천 시스템 구현"
끝. AI가 코드베이스를 분석하고, 기존 패턴을 파악하고, 구체적인 요구사항 명세서를 직접 작성합니다.
PDCA 4단계 상세:
/pdca plan → AI가 코드베이스 분석 후 Plan 문서 생성
→ 사람이 리뷰 & 승인 ✅
/pdca design → AI가 컴포넌트 설계, API 스펙, DB 스키마 설계
→ 사람이 리뷰 & 승인 ✅
/pdca do → AI가 구현 (이 단계만 자동)
→ Agent Teams 투입 가능
/pdca analyze → AI가 Design 문서 vs 실제 구현 Gap 분석
→ Match Rate 산출 (목표: 90% 이상)
→ 90% 미만이면 자동 반복 개선 (/pdca iterate)
→ 90% 이상이면 완료 리포트 생성 (/pdca report)
실제 결과 — 26개 피처의 Design Match Rate:
피처 | Match Rate | 반복 횟수 | 소요 시간 | Agent 수 |
|---|---|---|---|---|
B2B 멀티테넌시 플랫폼 | 100% | 0 | 1일 | 5 |
AI Coach 스킬 프로파일링 | 100% | 1 (80%→100%) | 1일 | 3 |
헤더 시스템 통합 (3→1) | 98% | 0 | 1시간 | - |
전체 한영 번역 (21개 파일) | 100% | 0 | 1일 | - |
채용 Assessment 시스템 | 96% | 0 | 1일 | 5 |
Arcade Dashboard 추천 엔진 | 99% | 0 | 2일 | - |
323개 문제 품질 개선 | 91% | 0 | 2일 | 8 |
Lab 문제 페이지 리뉴얼 | 93% | 1 (78%→93%) | 2일 | - |
평균 Match Rate: 96.5%
Self-Healing 시스템: AI가 실수하거나 놓치는 패턴을 발견하면, CLAUDE.md (프로젝트 규칙 파일)에 반영합니다. 예를 들어:
# CLAUDE.md에 추가된 실제 규칙들
## Next.js 16 주의사항
- Route Groups는 URL 세그먼트를 생성하지 않음: (lab)/dashboard → /dashboard
- 'use client' 파일에서 export const dynamic은 무시됨
- useAuth()는 SSR에서 AuthProvider 없이도 안전하게 동작해야 함
## API Client 규칙
- API_BASE_URL은 빈 문자열이어야 함 (API_ENDPOINTS에 /api 포함)
- 이중 프리픽스 (/api/api/...) 절대 금지
이 규칙들이 누적되면서 AI의 실수가 점점 줄어듭니다. 현재 CLAUDE.md는 65KB입니다.
3. Agent Teams: 역할 기반 병렬 개발
복잡한 피처는 전문화된 Agent Team을 구성합니다. 각 Agent는 명확한 역할, 파일 소유권, 작업 범위를 가집니다.
사례 1: B2B 플랫폼 구축 (5-Agent Team, 100% Match)
Project Manager (Lead) — 마일스톤 관리, 작업 분배
├─ DB Admin
│ → SQLAlchemy 모델 6개: Plan, Organization, Team,
│ Membership, Subscription, Invoice
│ → Alembic 마이그레이션 + 시드 데이터
│
├─ Backend Engineer
│ → FastAPI 엔드포인트 15개 (조직 10 + 빌링 5)
│ → RBAC 미들웨어 (org_owner > org_admin > team_admin > member)
│ → OrganizationService + BillingService
│
├─ Frontend Engineer
│ → Next.js 페이지 5개 (Dashboard, Teams, Members, Settings, Billing)
│ → React Query 통합, Skeleton Loading, Error States
│
├─ Pricing Strategist
│ → 3-tier 가격 모델 설계 (Team $29/seat, Business $49/seat, Enterprise)
│ → 볼륨 디스카운트, Feature Matrix
│
└─ Docs Writer
→ API Reference 15개 엔드포인트 문서화
→ DB 스키마 6개 테이블 문서화
결과: 28개 파일 생성/수정, 100% Design Match, 0 Gap, 1일 완료.
사례 2: 채용 Assessment 시스템 (5-Agent Team, 96% Match)
├─ Assessment Architect
│ → 서버 권위적 타이머 설계
│ → Proctoring 이벤트 모델링 (탭 전환, 복사/붙여넣기, 브라우저 이탈)
│
├─ Backend Engineer
│ → 18개 API 엔드포인트, 14개 URL 경로
│ → AssessmentService: 세션 라이프사이클 (draft/active/closed)
│ → SimilarityService: AST 기반 + 토큰 기반 코드 유사도 탐지
│ → ReportService: 등급/추천 엔진
│
├─ Frontend Engineer
│ → 3개 페이지, 7개 컴포넌트
│ → useAssessmentTimer, useProctoring, useAutoSave 훅
│
├─ Security Reviewer (Read-only)
│ → 서버 사이드 시간 검증 확인
│ → UniqueConstraint 중복 참가 방지 확인
│
└─ Problem Curator
→ Assessment용 문제 세트 큐레이션
결과: 4개 모델, 18개 엔드포인트, 40/40 QA 테스트 통과, 1일 완료.
사례 3: 200개 퀴즈 품질 리뷰 (7-Agent 병렬, 25개 CRITICAL 수정)
7개 Problem Curator Agent가 동시에 작업:
→ Agent 1-3: pytest, playwright, selenium 퀴즈 리뷰 (Phase 1)
→ Agent 4-7: api_testing, performance, security 퀴즈 리뷰 (Phase 2)
발견한 CRITICAL 이슈 예시:
- pytest-mocking-05: 잘못된 예외 타입 (ValueError → TypeError)
- playwright-locators-05: 잘못된 로케이터 전략
- performance 12개: 다중 인자 함수의 input_schema 누락
최종: 173 PASS (87%), 19 WARNING (10%), 0 CRITICAL. 2일 완료.
세 시스템의 융합: 실제 개발 사이클
피처 1: Arcade Dashboard 개인화 추천 시스템
/dev-init "arcade-dashboard-enhancement"
→ /pdca plan "랭크 기반 난이도 매칭, 취약점 분석(bug_type별 실패율),
도메인 탐색을 활용한 Rule-based 추천 엔진.
Top3 Picks + 카테고리 캐러셀 + Urgent Mission 타임어택"
→ /pdca design (API 스펙 2개, 컴포넌트 5개, 서비스 1개 설계)
→ /pdca do (구현)
→ /pdca analyze → 99% Match (116개 항목 중 115개 일치, 7개는 의도적 개선)
→ /dev-ship → sdetcode.com에 자동 배포
→ /dev-complete → main 병합
피처 2: Lab 문제 페이지 리뉴얼 (810줄 모놀리식 → 3파일 아키텍처)
/dev-init "lab-problem-page-renewal"
→ /pdca plan "810줄 page.tsx를 분해. Arcade 컴포넌트 6개 무수정 재사용.
ResizableSplitPanel + VS Code 스타일 에디터 탭 + 키보드 단축키 5개"
→ /pdca design
→ /pdca do
→ /pdca analyze → 78% Match (1차)
→ /pdca iterate → HintPanel 누락, History 탭 누락, 타입 중복 수정
→ /pdca analyze → 93% Match (2차) ✅
→ /dev-ship → /dev-complete
피처 3: 323개 문제 품질 일괄 개선 (8 Agent 병렬)
/dev-init "problem-quality-overhaul"
→ /pdca plan "QA Arena 79문제 + Arcade 200문제 + 번역 44문제 품질 개선"
→ 8개 Problem Curator Agent 병렬 투입
→ QA Arena PASS Rate: 82% → 94%
→ 25개 CRITICAL 이슈 발견 및 수정
→ /dev-ship → /dev-complete
Dangerous Mode + PDCA = 통제된 자율성
Claude Code를 auto-approve 모드(일명 Dangerous Mode)로 실행합니다. 파일 수정, 커맨드 실행에 일일이 확인하지 않습니다.
위험해 보이지만, PDCA가 안전망 역할을 합니다:
/pdca plan → 사람이 리뷰 & 승인 ✋ (여기서 방향 확인)
/pdca design → 사람이 리뷰 & 승인 ✋ (여기서 설계 확인)
/pdca do → AI 자율 실행 🤖 (유일한 YOLO 구간)
/pdca analyze → AI가 Gap 분석 → 사람이 결과 확인 ✋
Plan과 Design에서 이미 "무엇을 어떻게 만들지" 합의했기 때문에, Do 단계에서 AI가 벗어날 여지가 적었습니다.
실제 운영 캡쳐 파일
1. Dev-init을 통한 Development Cycle 시작
Dev-init 완료 후 pdca 계획 요청
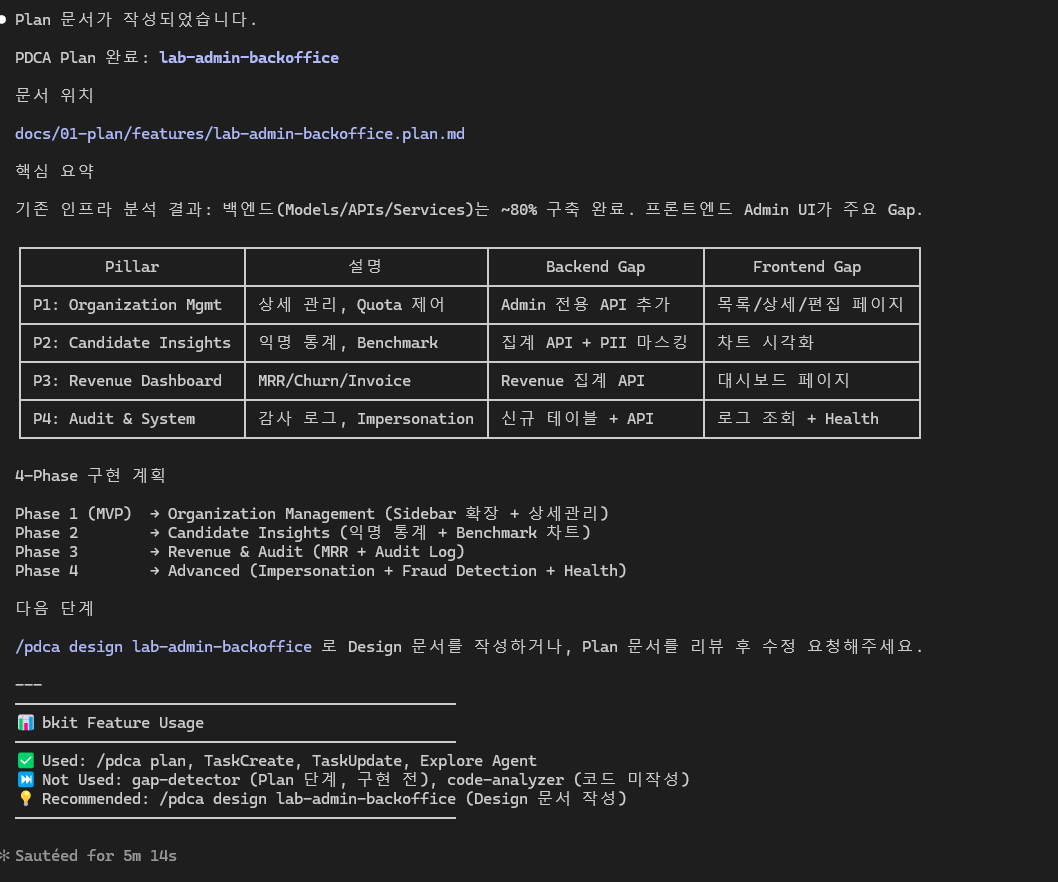
pdca plan 계획서 제작
Gemini Pro 활용하여 Plan 문서 보강

2개의 Task 동시 구현
Lab Dashboard
Arcade 내 문법 오류 검토
Agent Team 구동 장면
Front Engineer
Backend-Engineer