AI에게 존대말을 쓰면 똑똑해진다?
재밌는 글이 보여 퍼왔습니다다.
출처: 황민호님 페이스북
AI에게 존댓말을 쓰면 정말 더 똑똑해질까요?
AI를 기계가 아니라 대화형 에이전트로 대할 때(특히 존댓말/공손한 톤),
답변 품질을 끌어올릴 확률이 커진다는 관점에서 정리해보았습니다.
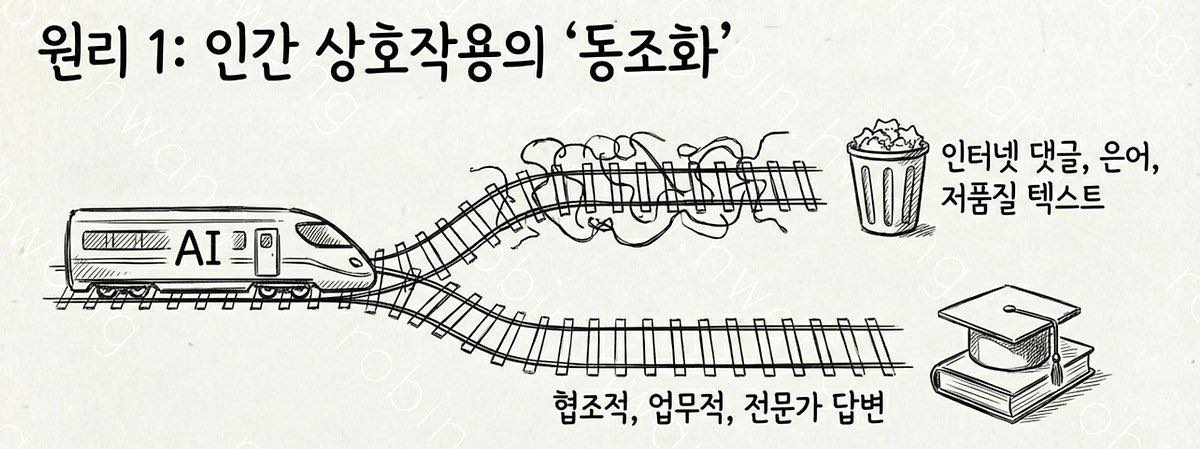
👁️🗨️ 인간 상호작용의 “동조화”를 유도합니다
대부분의 대화형 LLM은 사람의 선호에 맞추도록 인간 피드백 기반 학습(RLHF 등)을 거쳐 “좋은 대답” 패턴을 강화합니다. 그래서 사용자가 존댓말로 요청·맥락·제약을 대화 규칙에 맞게 제시하면, 모델이 학습 과정에서 자주 보았던 ‘협조적/업무적 대화’ 레일로 더 잘 올라타는 경향이 있습니다. AI가 예의를 느껴서가 아니라, 대화 구조 신호가 늘기 때문입니다.
예: “~해 주세요”, “형식은 표로”, “근거를 적어줘”
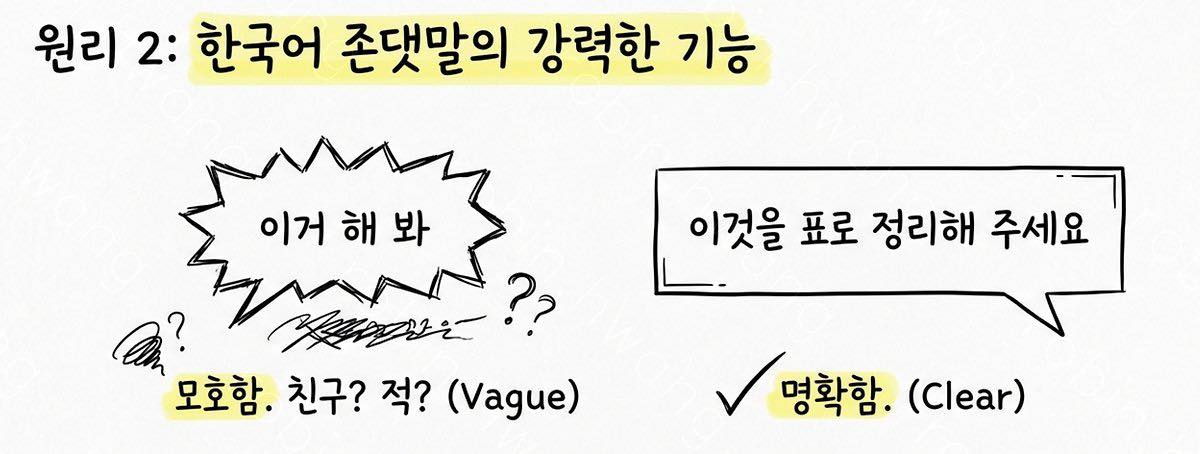
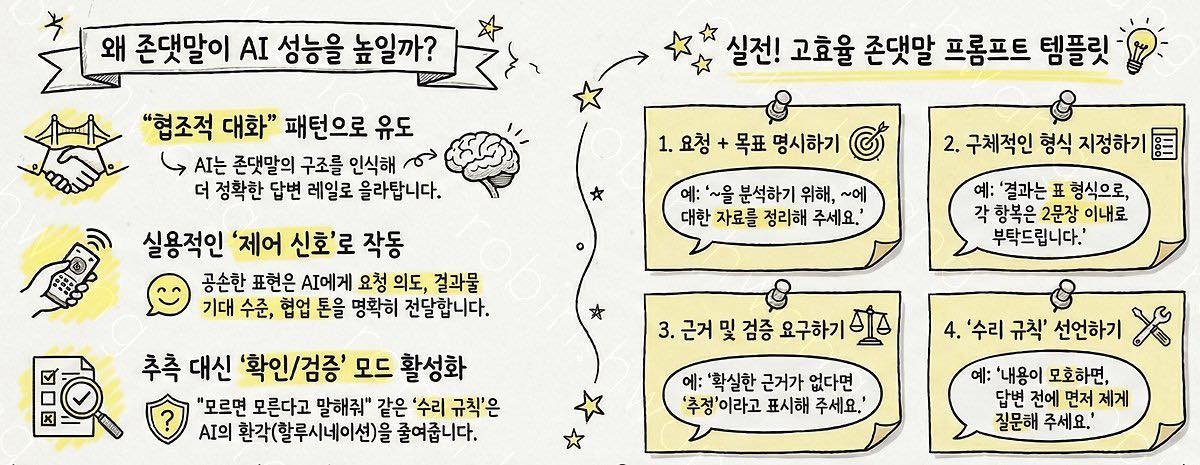
👁️🗨️ 공손성은 예절이 아니라, 실용적인 제어 신호입니다.
공손한 표현은 단순 장식이 아니라, 모델에게 의도(요청), 기대(상세히), 톤(협업적)을 함께 전달하는 프롬프트 구성요소로 작동합니다. 전문가들도 “공손한 톤이 답변의 협업적/존중하는 톤을 유도하고, 입력의 전문성·명확성을 반영한다”는 취지로 설명합니다. 특히 한국어에서는 존댓말 자체가 요청의 모드(명령 vs 부탁), 관계(협업), 문장 완결성을 명확히 만들어서 지시사항이 덜 뭉개집니다.
단, 과하게 공손한 장문 간접화법은 오히려 요구사항을 흐릴 수 있습니다. “혹시 괜찮으시다면… 가능하실까요…”가 길어질수록 핵심 제약이 묻힐 수 있음
👁️🗨️ “수리 (대화 바로잡기)”를 명시하면 할루시네이션을 더 잘 통제합니다.
대화분석에서 수리(repair)는 대화 중 생기는 말하기/듣기/이해의 문제를 탐지하고 바로잡는 절차를 뜻합니다. LLM의 할루시네이션은 “그럴듯하게 이어가기” 성향에서 자주 나오는데, 사용자가 존댓말로 수리 규칙을 선제 선언하면 모델이 추측 대신 확인/정정 루프로 들어갈 확률이 올라갑니다.
예: “확실하지 않으면 모른다고 말하고, 근거를 제시해 주세요”, “애매하면 먼저 질문해 주세요”, “틀리면 정정해 주세요”
👁️🗨️ 연구 관점의 보완: “정중함이 항상 만능은 아니지만, 무례함은 리스크가 커진다”
프롬프트의 정중함이 성능에 미치는 영향은 언어·과제에 따라 달라질 수 있습니다. 다만 영어·중국어·일본어를 비교한 연구에서는 무례한 프롬프트가 성능을 떨어뜨리는 경우가 많고, “너무 공손하다고 항상 더 좋아지는 건 아니며, 언어권별 최적 수준이 다르다”고 보고합니다.
관련 연구 : https://arxiv.org/abs/2402.14531
실전 결론: 짧고 명확한 존댓말 + 구체 제약 + 수리 규칙이 가장 안전한 고효율 조합입니다.
바로 써먹는 존댓말 템플릿 (핵심만)
- 요청+목표: “~을 위해, ~을 정리해 주세요.”
- 형식: “불릿 5개, 각 항목 2문장으로 부탁드립니다.”
- 근거/검증: “확실한 근거가 없으면 추정이라고 표시해 주세요.”
- 수리 규칙: “모호하면 먼저 질문해 주세요. 틀린 부분은 정정해 주세요.”