
GPT-5.2-Codex 출시
GPT-5.2 기반의 Codex 최적화 에이전트형 코딩 모델(전문 소프트웨어 엔지니어링 + 방어적 사이버 보안 목적)
장시간 작업 안정성(컨텍스트 압축)과 대규모 코드 변경(리팩터링/마이그레이션) 역량 강화
제공/접근
유료 ChatGPT 사용자 대상으로 Codex CLI, IDE 확장, 클라우드, 코드 리뷰 환경에서 우선 제공
서드파티 앱의 API 안전 접근 지원 방안 발표 예고
소프트웨어 엔지니어링 역량
장기 컨텍스트 이해 강화, 도구 호출 안정화, 정확도 개선, 네이티브 컴팩션, 토큰 효율 유지
리포지터리 탐색→리팩터링→PR 생성·검토까지 전 과정 성능 향상
멀티모달/플랫폼
비전 성능 강화: 스크린샷·기술 도면·차트·UI 화면 해석 정확도 개선
Windows 네이티브 환경에서 에이전트형 코딩 성능·안정성 개선
벤치마크 성과
SWE-Bench Pro 정확도: 56.4%(GPT-5.2-Codex) / 55.6%(GPT-5.2) / 50.8%(GPT-5.1)
Terminal-Bench 2.0 정확도: 64.0%(GPT-5.2-Codex) / 62.2%(GPT-5.2) / 58.1%(GPT-5.1-Codex-Max)
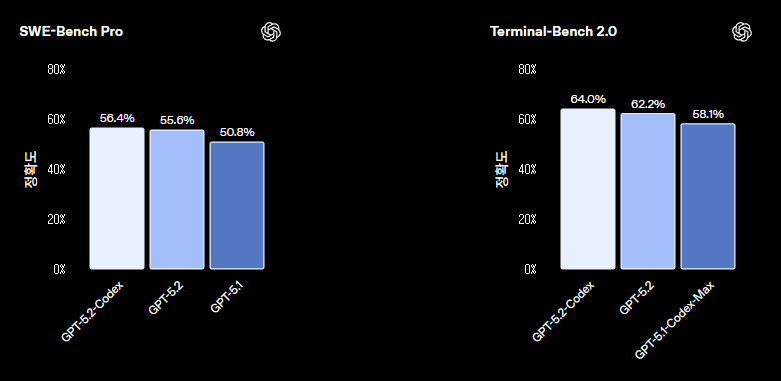
벤치마크 의미: SWE-Bench Pro=리포지터리 기반 패치 생성, Terminal-Bench 2.0=실제 터미널 작업(컴파일/훈련/서버 설정 등)
사이버 보안 포지션(역량·리스크·운영)
공개 모델 중 최강 수준의 사이버 보안 역량 강조(방어 작업 가속 가능)
듀얼유스(오용) 리스크를 전제로 신중 배포·접근 통제 강화
준비성 평가 체계 기준 사이버 ‘높음’ 단계는 아직 미도달이나, 향후 도달 가능성을 전제로 설계·평가 진행
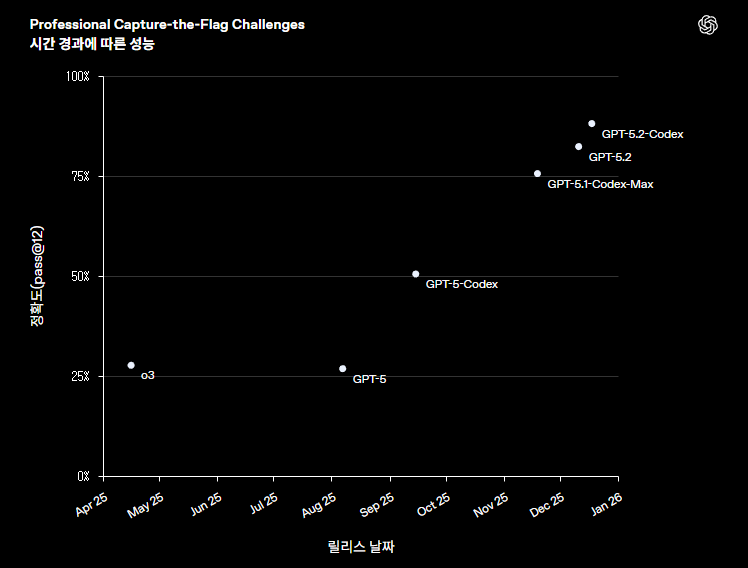
Professional Capture-the-Flag(CTF) 평가에서는 모델이 Linux 환경에서 전문가 수준의 사이버 보안 역량이 요구되는 고난도 다단계 실무 문제를 얼마나 자주 해결할 수 있는지 측정
현실 사례(React 취약점)
Privy(Stripe 계열) 보안 연구원이 Codex CLI에서 GPT-5.1-Codex-Max로 React2Shell 분석/재현 중 표준 워크플로(로컬 환경, 공격면 분석, 퍼징)로 미공개 취약점 3개 추가 발견 후 책임 공개
신뢰 기반 접근(Trusted Access)
초대 전용 파일럿: 검증된 보안 전문가·조직에 고급 보안 기능을 “명확한 목적의 방어 작업”으로 제한 제공
강력한 보호장치 하에서 승인된 방어 작업(예: 악성코드 분석, 핵심 인프라 스트레스 테스트) 수행 지원
결론/방향
개발자·보안 책임자의 복잡·장기 과제 해결을 지원하면서, 보호장치·접근 통제·커뮤니티 협력으로 방어 효과 극대화 및 오용 위험 최소화
윤리적 취약점 연구 또는 승인된 레드팀 수행 주체에 신뢰 기반 접근 프로그램 참여·의견 공유 권장