
OpenAI GPT‑5.1-Codex-Max 출시
Codex에서 사용 가능한 새로운 프론티어 에이전트 코딩 모델.
기반 기술: 소프트웨어 엔지니어링, 수학, 연구 등 에이전트 작업을 학습한 기초 추론 모델 업데이트 버전.
주요 특징:
개발 전 단계에서 더 빠르고, 지능적이며, 높은 토큰 효율성 제공.
장기 작업 최적화:
압축(Compaction) 기술 최초 적용: 여러 컨텍스트 윈도우를 넘나들며 작동.
단일 작업에서 수백만 개의 토큰을 일관성 있게 처리.
프로젝트 규모 리팩토링, 심층 디버깅, 장시간 에이전트 루프 수행 가능.
사용 가능 플랫폼: Codex CLI, IDE 확장 프로그램, 클라우드, 코드 리뷰 (API 곧 출시).
최첨단 코딩 역량 (Frontier coding capabilities)
훈련 데이터: PR 생성, 코드 리뷰, 프론트엔드 코딩, Q&A 등 실제 소프트웨어 엔지니어링 작업 기반.
성능: 다수 최첨단 코딩 평가에서 이전 모델 상회.
실사용 개선:
최초로 윈도우(Windows) 환경 작동 훈련.
Codex CLI 협업 능력 강화를 위한 작업 훈련 포함.
벤치마크 비교
compaction활성화,extra high(xhigh)reasoning 기준)
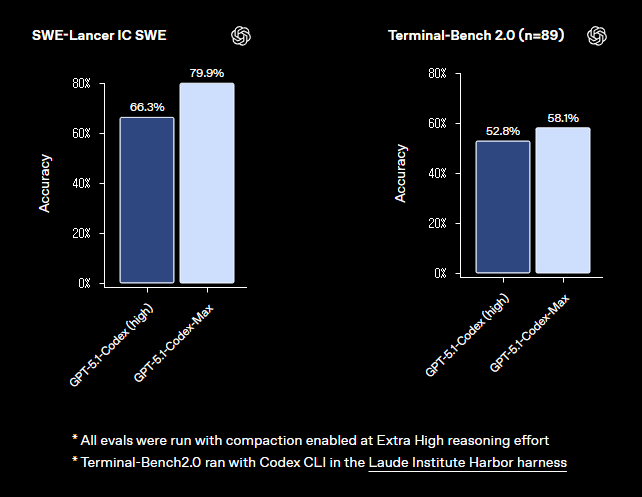
속도 및 비용 (Speed and cost)
토큰 효율성: 효과적인 추론 능력으로 효율성 대폭 향상.
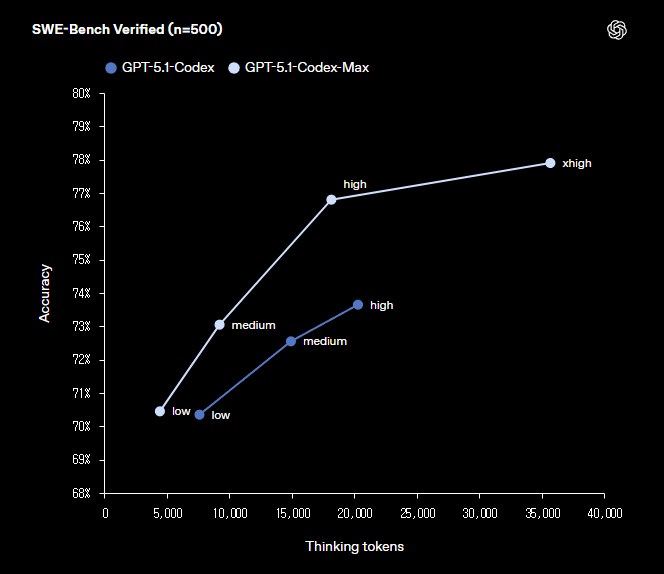
SWE-bench Verified 결과:
'중간(medium)' 노력 단계 기준, 기존 모델 대비 성능 우위.
생각 토큰(thinking tokens) 30% 절감.
reasoning effort 단계:
Extra High(‘xhigh’): 지연 시간에 민감하지 않은 작업을 위해 신설 (더 오래 생각하여 품질 향상).
중간(Medium): 일상적인 작업용으로 권장.
비용 절감: 토큰 효율성 개선이 실질적 개발 비용 절감으로 연결.
예: GPT‑5.1-Codex보다 훨씬 저렴한 비용으로 고품질 프론트엔드 디자인 제작.
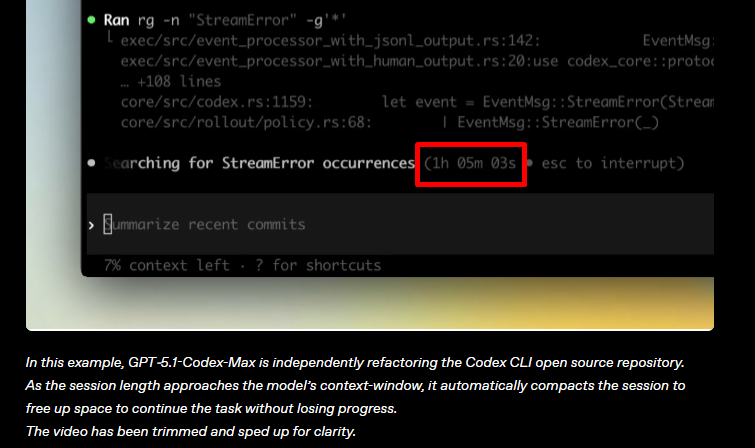
장기 실행 작업 (Long-running tasks)
압축(Compaction) 기능:
기존 컨텍스트 한계로 실패하던 작업(복잡한 리팩토링, 장시간 루프 등) 해결.
가장 중요한 맥락은 보존하고 기록을 정리(pruning).
작동 메커니즘: 세션이 한계에 도달하면 자동 압축 -> 새로운 윈도우 확보 -> 완료 시까지 반복.
지속성:
범용적이고 신뢰할 수 있는 AI의 기반 능력.
한 번에 수 시간 독립 작업 가능 (내부 평가서 24시간 이상 작업 확인).
구현 반복, 테스트 오류 수정, 최종 결과 도출까지 수행.
안전하고 신뢰할 수 있는 AI 에이전트 구축 (Building safe and trustworthy AI agents)
평가 성과: 압축 기능을 통해 장기 추론, 코딩, 사이버 보안 분야에서 성과 향상.
사이버 보안 역량:
'Preparedness Framework' 기준 '높음(High)' 미달이나 역대 최고 수준 능력 보유.
빠르게 진화하는 역량에 맞춰 안전장치 강화 및 Aardvark 프로그램 등으로 방어자 지원.
모니터링 및 대응:
보안 전용 모니터링 가동 중 (대규모 악용 사례 없음).
고급 기능에 대한 추가 완화 조치 준비 및 악의적 시도 차단.
샌드박스 및 보안:
기본적으로 보안 샌드박스 실행 (파일 쓰기 제한, 네트워크 비활성).
인터넷 활성화 시 프롬프트 인젝션 위험 존재 -> 제한 모드 권장.
검토 중요성:
장기 작업 수행 시 배포 전 인간 검토 필수.
터미널 로그, 툴 호출, 테스트 결과 제공으로 검토 지원.
Codex는 인간을 대체하는 것이 아닌 'additional reviewer' 역할.
배포 접근법: 방어/공격 양면성을 고려한 반복적 배포 및 방어 도구(취약점 스캔 등) 보존.
이용 안내 (Availability)
대상 요금제: ChatGPT Plus, Pro, Business, Edu, Enterprise.
API: CLI/API 키 사용자를 위해 곧 출시 예정.
기본 모델 변경: 오늘부터 GPT‑5.1-Codex를 대체하여 기본 모델로 적용.
권장 사항: 에이전트 코딩 작업에는 GPT‑5.1-Codex-Max 및 Codex 제품군 사용 권장 (범용 GPT‑5.1과 구분).
부록: 모델 평가 (Appendix: Model evaluations)
벤치마크 | GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) |
SWE-bench Verified (n=500) | 73.7% | 77.9% |
SWE-Lancer IC SWE | 66.3% | 79.9% |
Terminal-Bench 2.0 | 52.8% | 58.1% |