
Gemini 3 Pro 모델 카드 유출 및 정보.pdf
모델 개요
Gemini 3 Pro는 Gemini 시리즈의 차세대 멀티모달 추론 모델로, 현재 Google의 가장 고급 Pro 모델.
텍스트·이미지·오디오·비디오·코드 저장소 등 다양한 소스를 이해하며, 복잡한 추론과 대규모 데이터 처리에 특화.
입력 컨텍스트는 최대 100만 토큰, 출력은 최대 64K 토큰 지원.
Sparse Mixture-of-Experts(MoE) 기반 트랜스포머 구조로, 일부 전문가만 활성화해 성능과 비용을 분리.
학습 데이터
공개 웹 문서, 코드, 이미지, 오디오, 비디오 등 대규모·다양한 데이터 사용.
크롤링 데이터, 라이선스 데이터, Google 서비스 사용자 데이터(약관·프라이버시 정책·사용자 설정에 따라), 사내 생성 데이터, 합성 데이터 포함.
중복 제거, robots.txt 준수, 안전 필터링, 품질 필터링 등을 통해 유해·저품질 데이터를 걸러내는 전처리 수행.
학습 및 인프라
Google TPU 및 TPU Pod를 활용해 대규모 분산 학습 수행.
고대역폭 메모리와 대규모 클러스터로 대형 모델·배치 처리에 최적화.
소프트웨어 스택은 JAX와 Pathways 기반.
배포 채널
Gemini App, Google Cloud Vertex AI, Google AI Studio, Gemini API, Google AI Mode, Google Antigravity 등 다양한 채널로 제공.
주로 API 형태로 제공되며, 각 플랫폼별 추가 약관과 사용 정책이 적용됨.
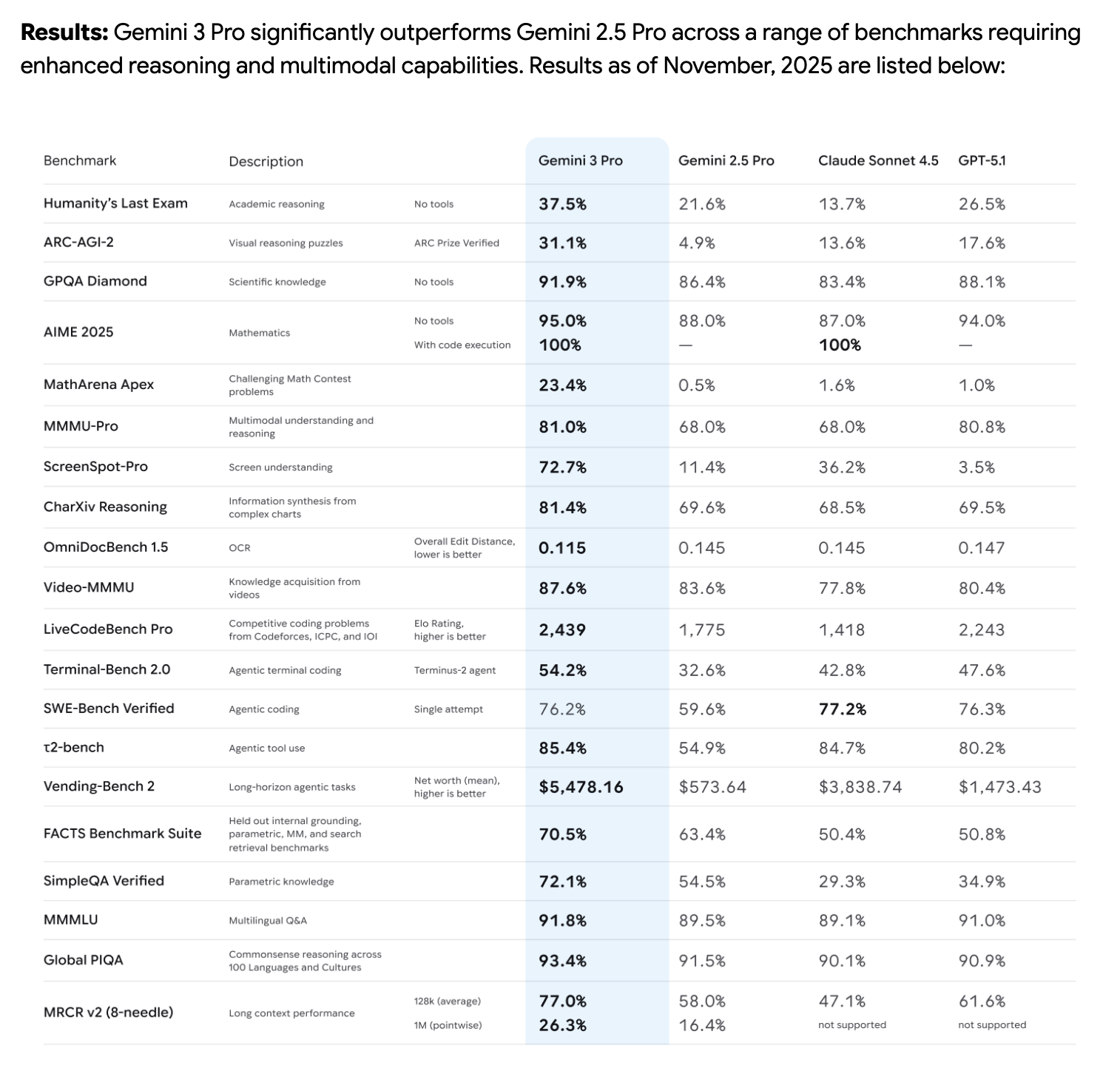
성능 평가
추론, 멀티모달, 에이전트형 툴 사용, 다국어, 롱컨텍스트 등 다양한 벤치마크로 평가.
전반적으로 Gemini 2.5 Pro 대비 추론·멀티모달 성능이 유의미하게 향상.
상세 점수·벤치마크는 별도 평가 페이지에서 제공.
https://deepmind.google/models/evals/gemini-3-pro/ (25-11-18 20:57 기준 닫혀있음)
의도된 활용과 한계
복잡한 현실 문제 해결, 고급 코딩, 장문 컨텍스트 처리, 멀티모달 이해, 알고리즘 개발 및 에이전트형 사용 사례에 적합.
여전히 환각(hallucination), 속도 저하, 타임아웃 등의 일반적인 한계 존재.
지식 컷오프는 2025년 1월.
Google의 Generative AI 금지 사용 정책에 따라, 불법·위험·폭력·성적·혐오·허위정보 등의 용도로 사용 금지.
윤리·콘텐츠 안전
개발 과정에서 안전·보안·책임팀과 협업, Google AI 원칙 및 Gen AI 정책을 준수.
자동·수동 평가, 휴먼/자동 레드팀, 윤리·안전 리뷰 등 다단계 평가 수행.
텍스트·이미지·다국어 안전 평가에서 Gemini 2.5 Pro 대비 전반적인 안전성과 톤이 개선되면서도, 불필요한 거부 비율은 낮게 유지.
데이터 필터링, 조건부 프리트레이닝, SFT, RLHF·크리틱 피드백, 정책·필터링 등 다양한 완화(mitigation) 기법 적용.
주요 위험과 완화
여전히 남아 있는 위험
탈옥(jailbreak) 취약성
다중 턴 대화에서의 성능 저하 가능성.
위험 완화를 위해 모델 전·후처리, 정책, 제품 레벨 필터 등 다층 방어 구조 운용.
프론티어 안전(Frontier Safety)
Google DeepMind의 Frontier Safety Framework(2025년 버전)에 따라 CBRN, 사이버 보안, 조작, ML R&D 가속, 오용 가능성 등을 평가.
CBRN, 사이버 공격, 해로운 조작, 고도 자동화 등 어떤 영역에서도 ‘중요 능력 수준(Critical Capability Level)’에는 도달하지 않은 것으로 판단.
일부 영역에서 기존 모델 대비 향상은 있으나, 위협 행위자의 능력을 비약적으로 끌어올릴 정도의 수준에는 미달.